
NVivo – 頻出語からノードを作成
頻出語クエリの結果からノードを作成することができます。まず、プロジェクト内のインタビューデータを対象に頻出語を表示してみます。
リボン[探索]→[頻出語]をクリックします。
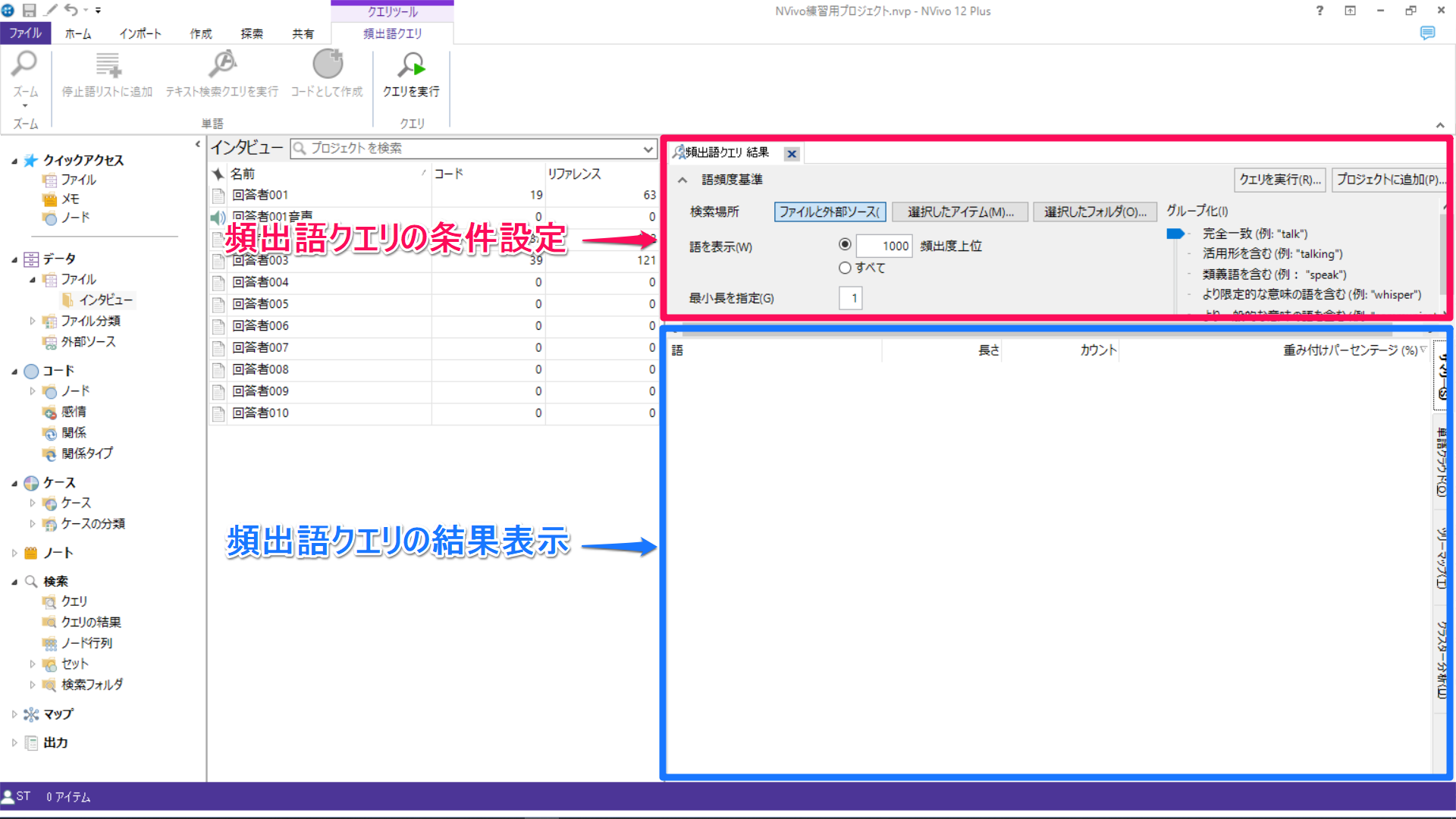
頻出語クエリの画面が開きます。上部で条件を指定、下部に結果が表示されます。
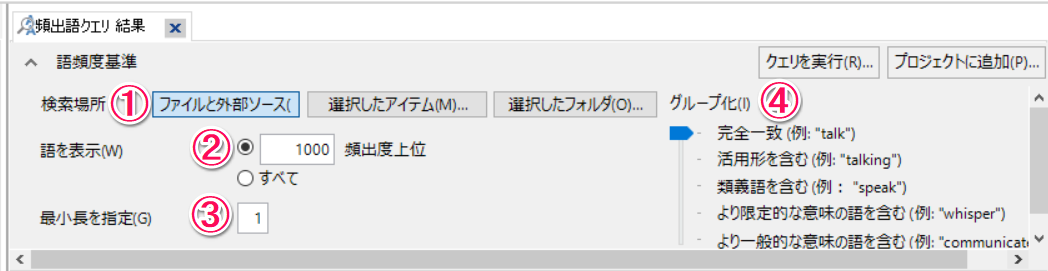
頻出語クエリの以下条件を指定します。
① どのファイルを対象とするか指定。
② 頻度の高い語上位何語までを表示するかを指定。
③ 何文字以上の語を対象とするかを指定。例えばここを「3」にすると2文字の語(例:場所)は対象外となる。
④ 活用形を含める、類義語を含めるのようなグループ化の程度を指定。
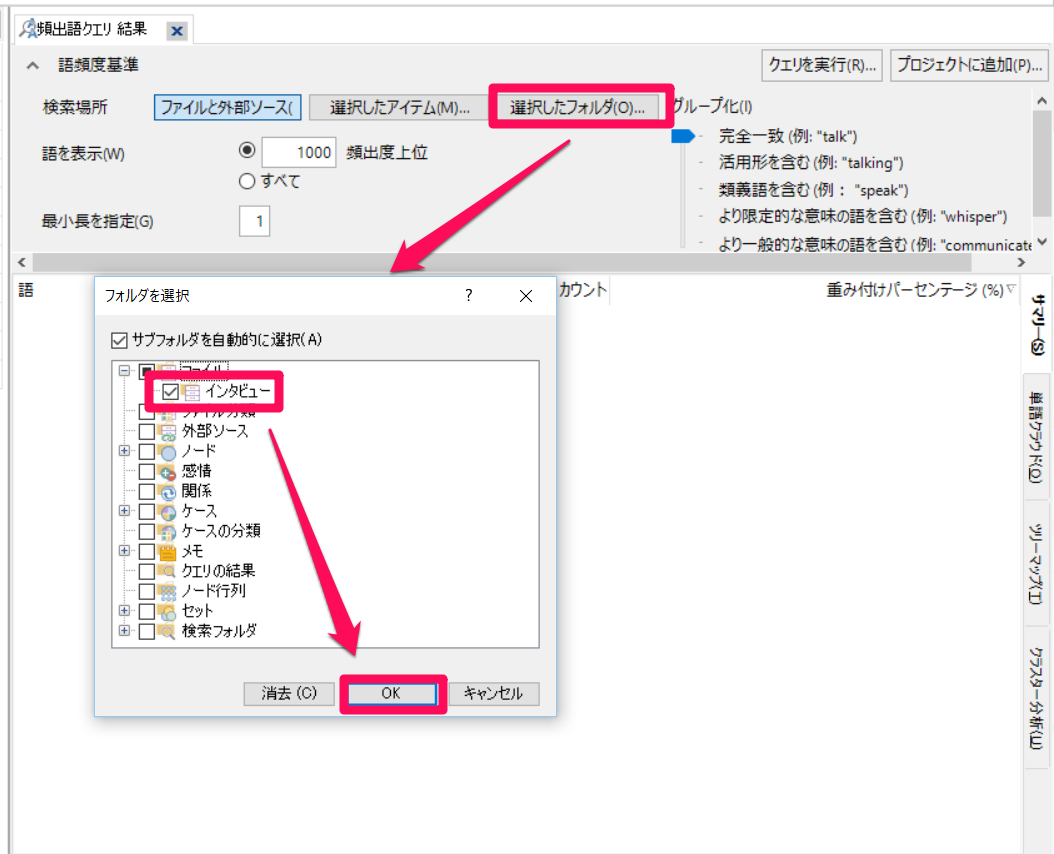
今回は、①で[選択したフォルダ]→「\\ファイル\インタビュー」を選択し、インタビューフォルダに保存されているファイルのみを対象にしていします。
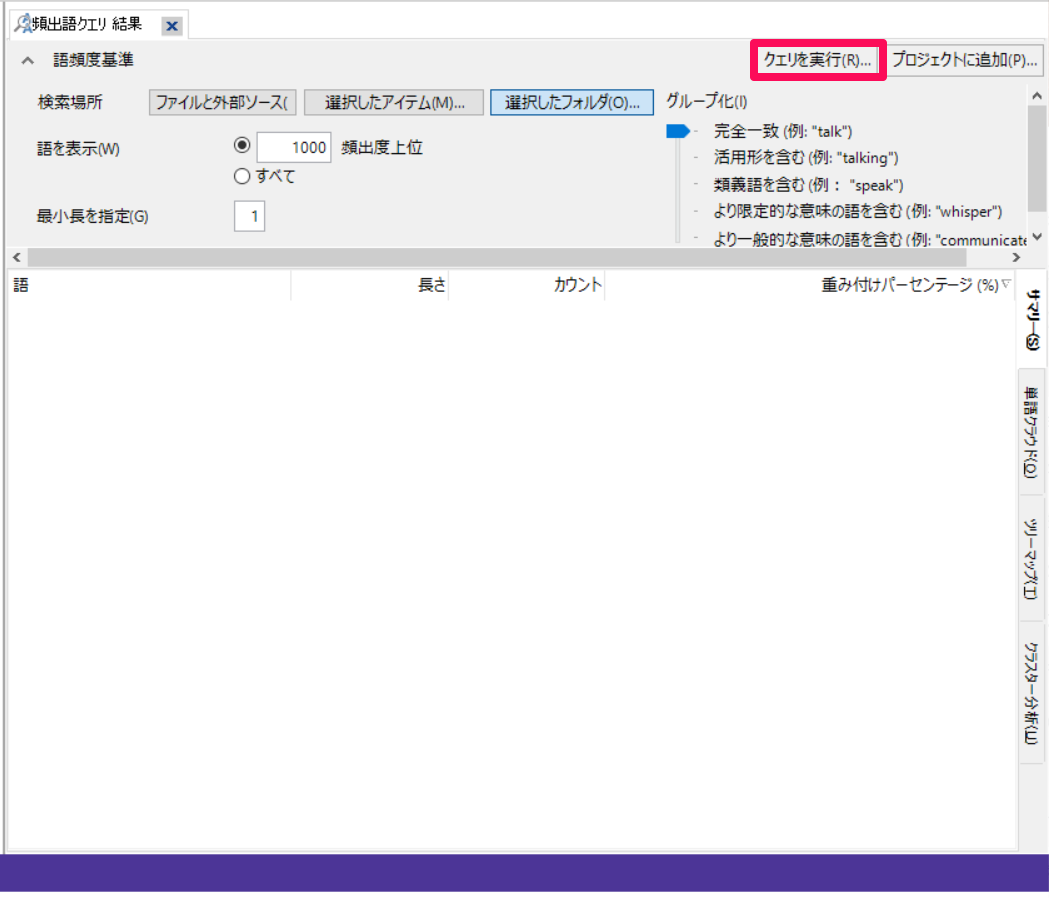
指定を完了したら[クエリを実行]をクリック。
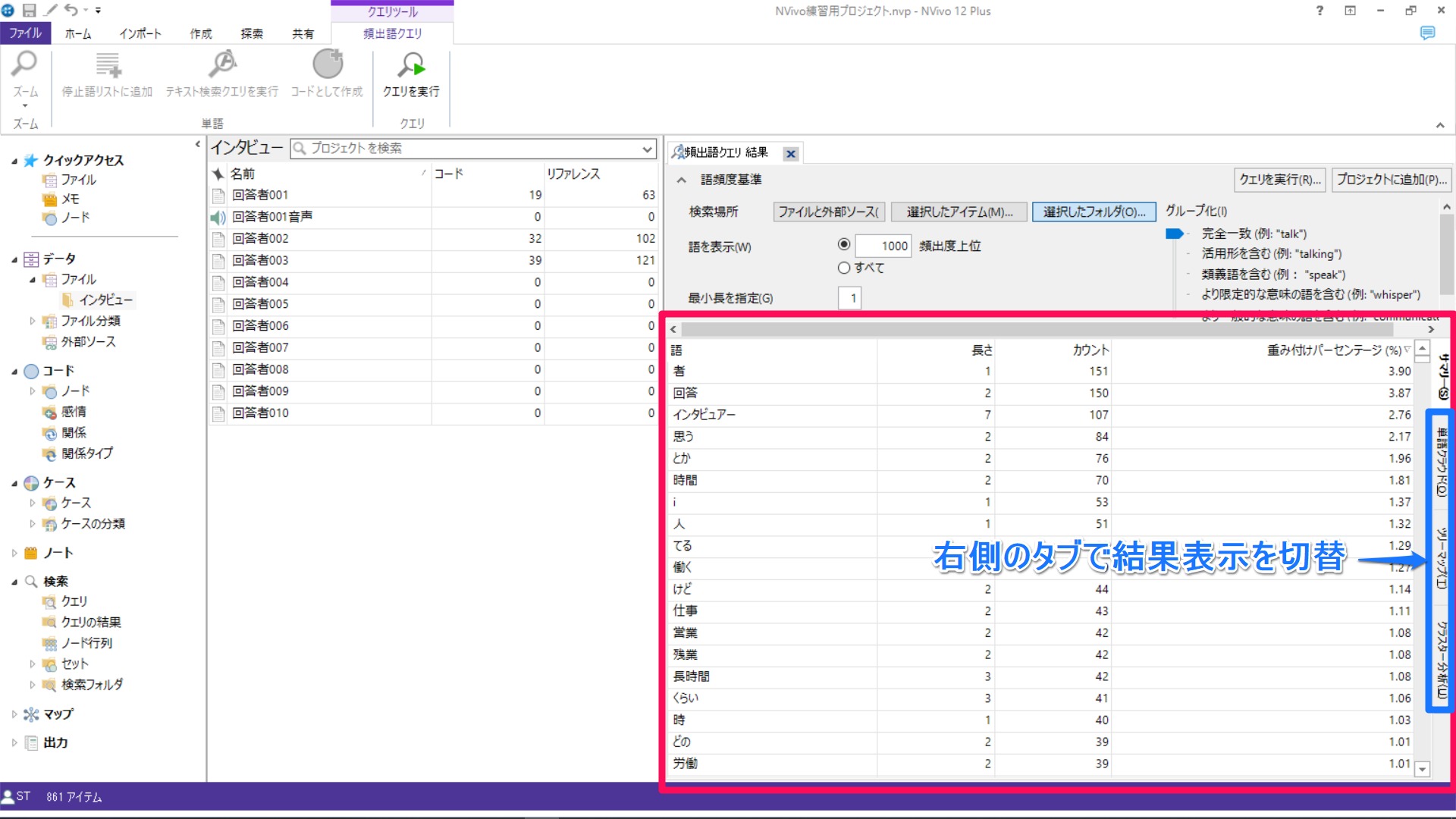
結果が表示されます。右側のタブで結果の表示を切り替えられます。[単語クラウド]を見てみましょう。
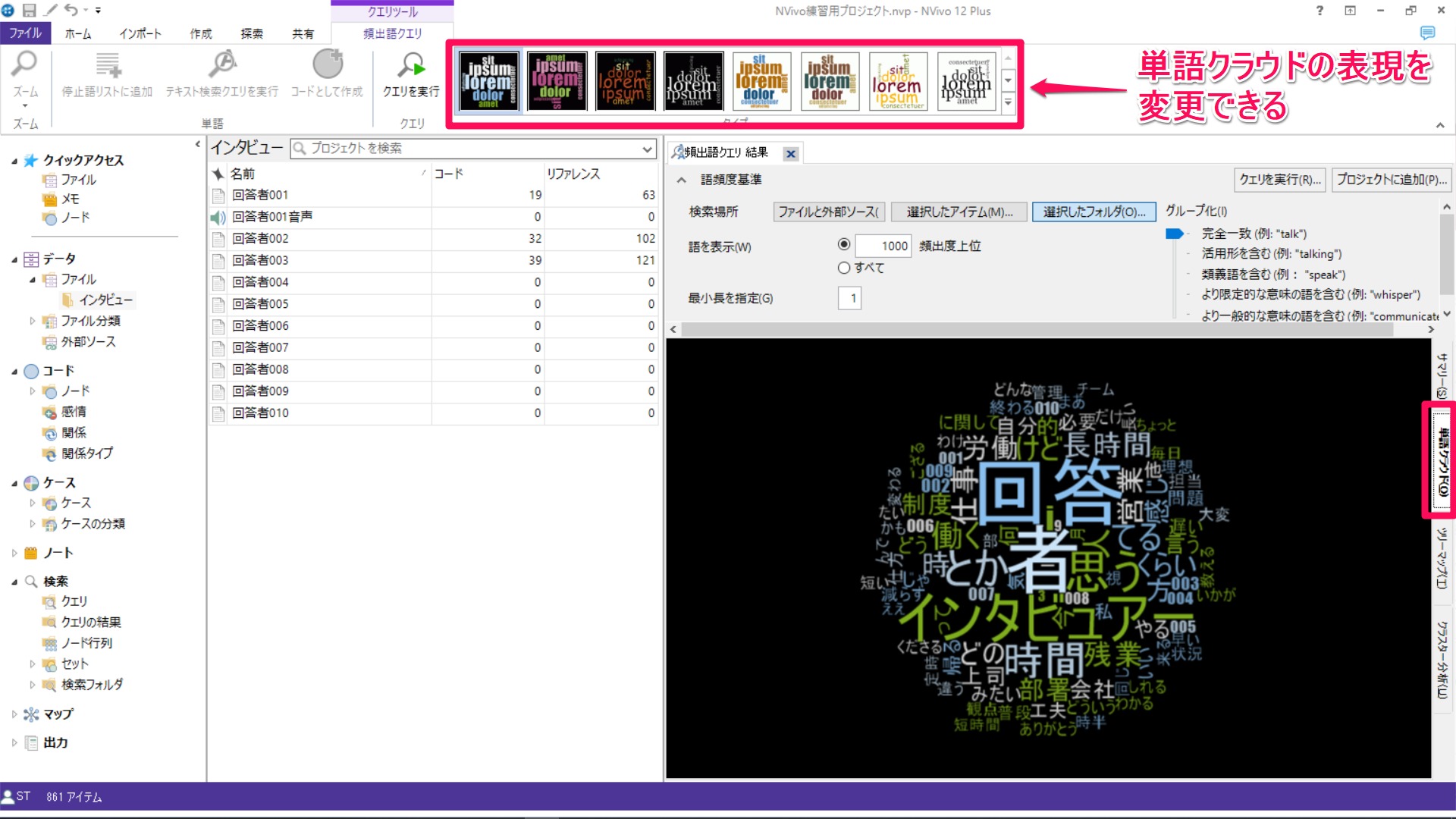
単語クラウドでは、出現頻度上位100語が、頻度の高い語は大きく、低い語は小さく表示されます。リボンの[クエリツール]で、単語クラウドの表現を変更することも可能です。
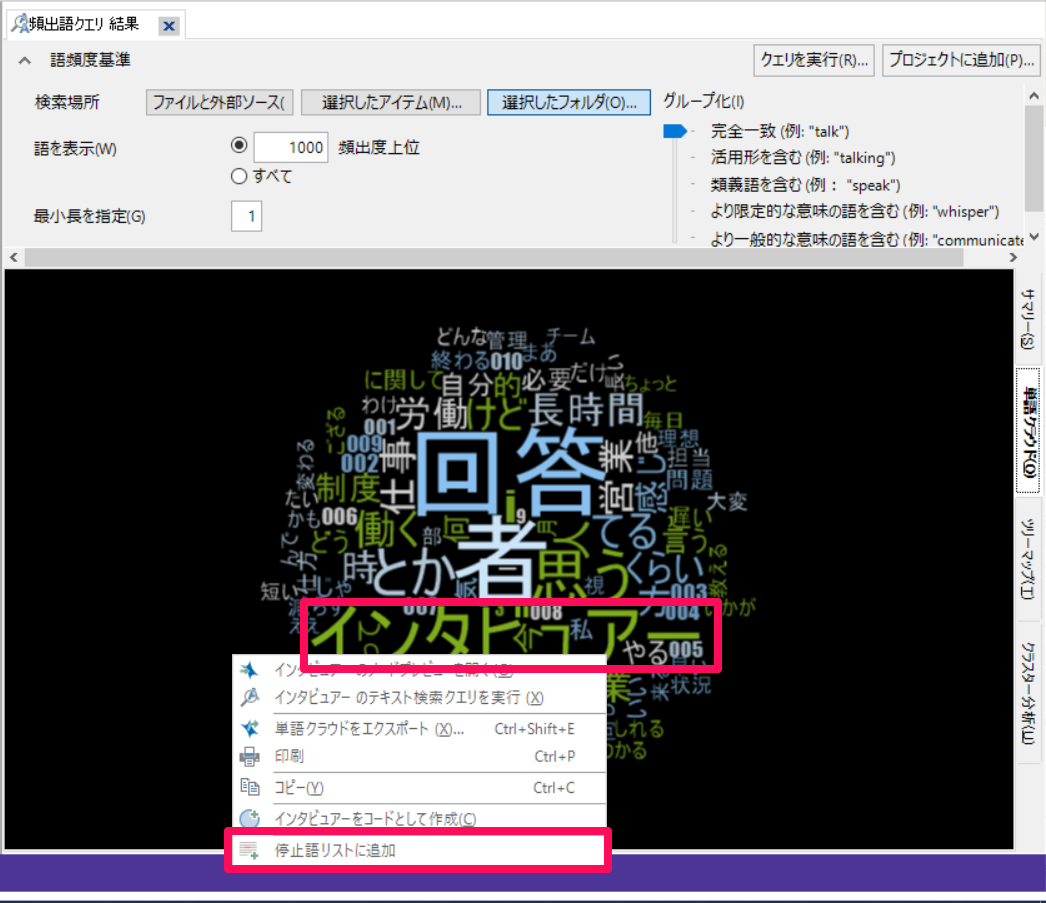
不要な語を省きたい場合は、省きたい語の上で右クリック→[停止語リストに追加]を選択します。
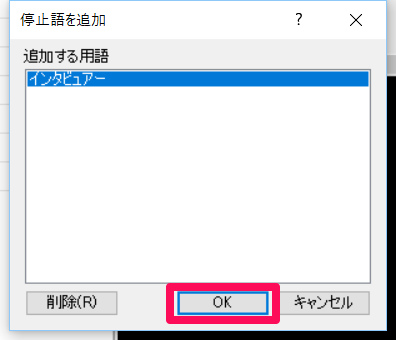
[OK]をクリックで、選択した語(ここでは「インタビュアー」)が停止語リストに追加されます。確認のため、再度[クエリを実行]してみましょう。
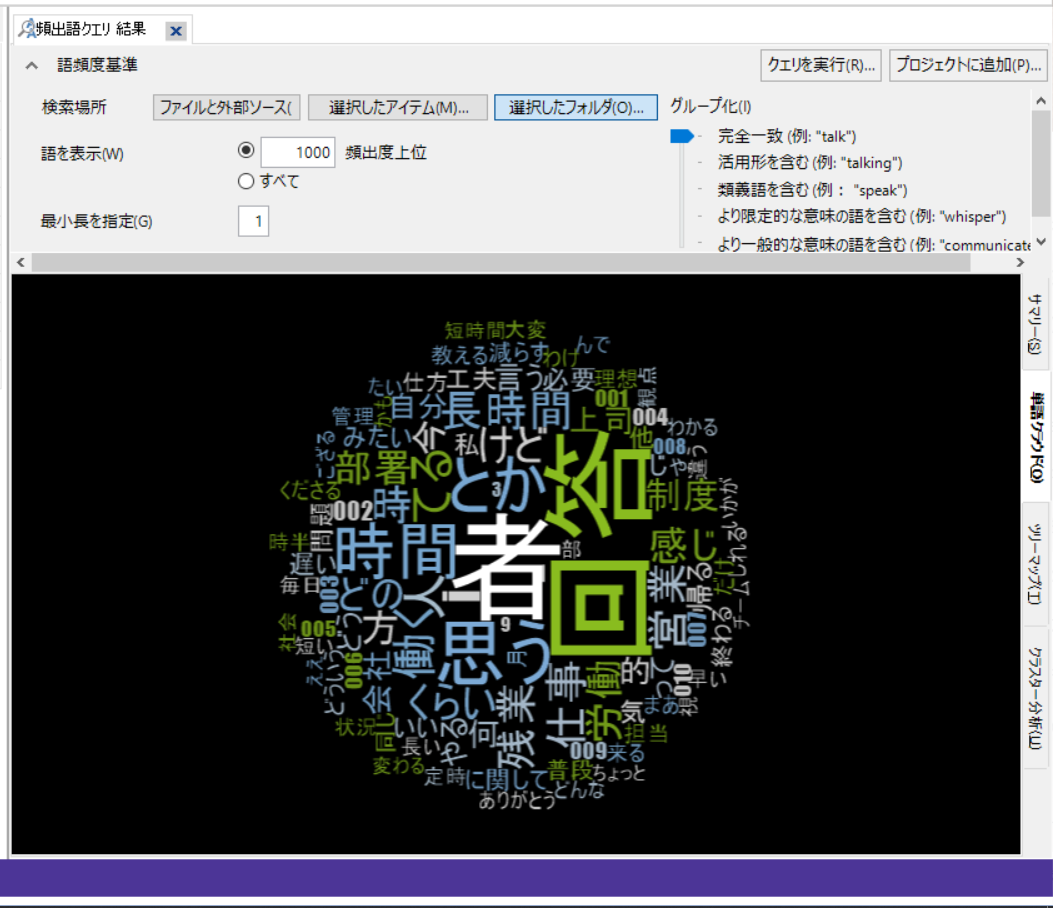
「インタビュアー」が結果から省かれていることを確認できます。
停止語リストは、プロジェクトファイルごとに管理されています。[ファイル]→[オプション]を開き、[ストップワード]をクリックすると、テキストファイルで編集可能になります。
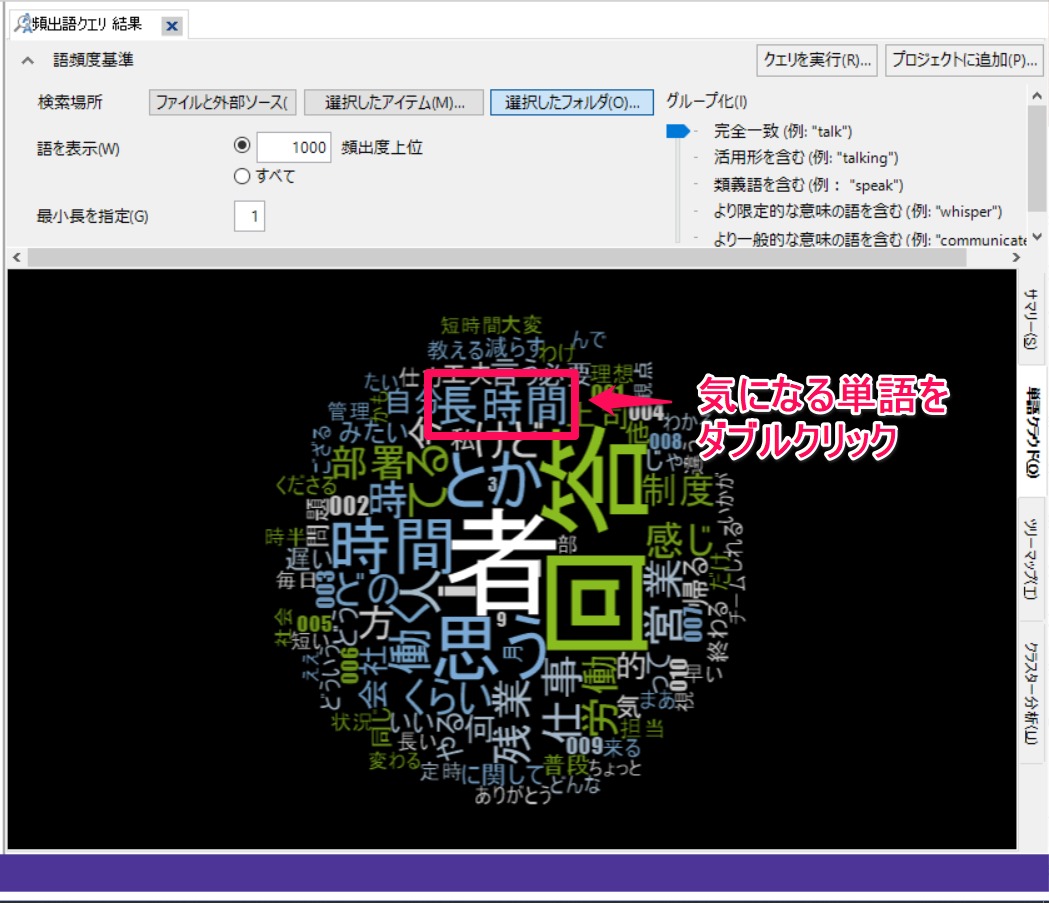
気になる単語をダブルクリックするとその後が含まれるコンテンツを確認できます。
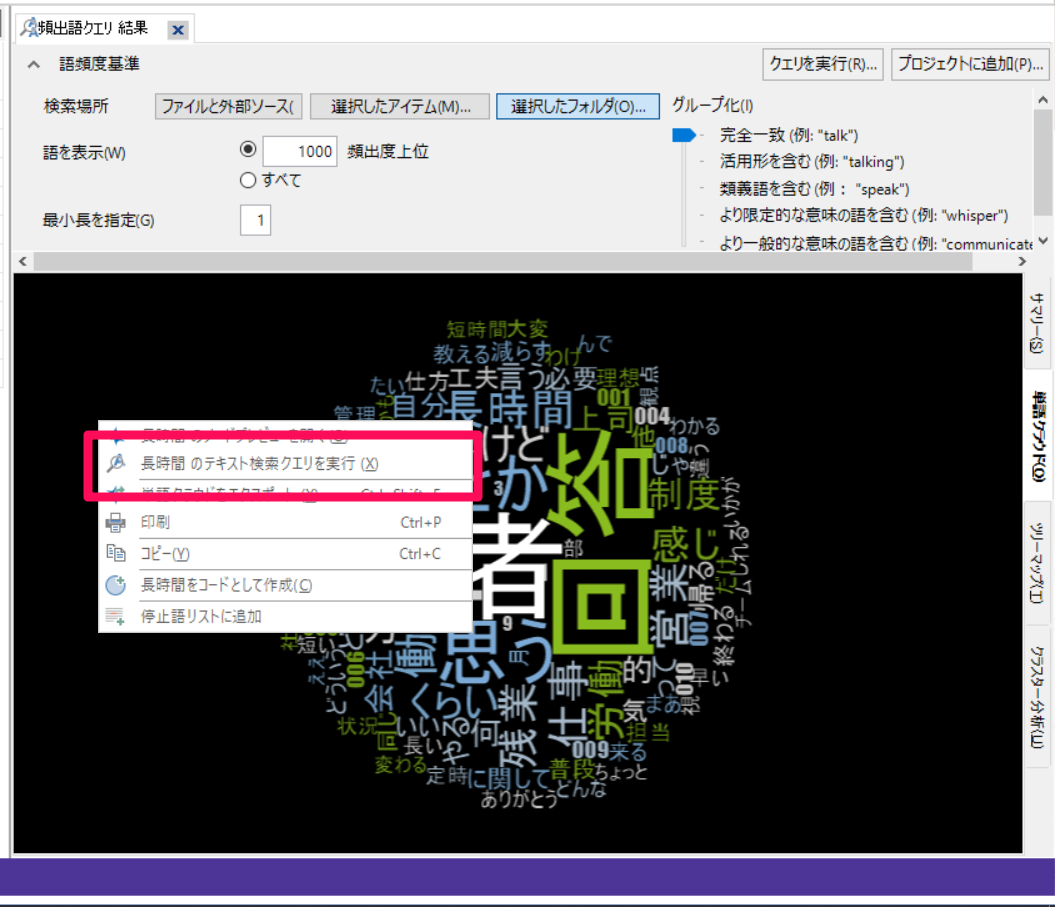
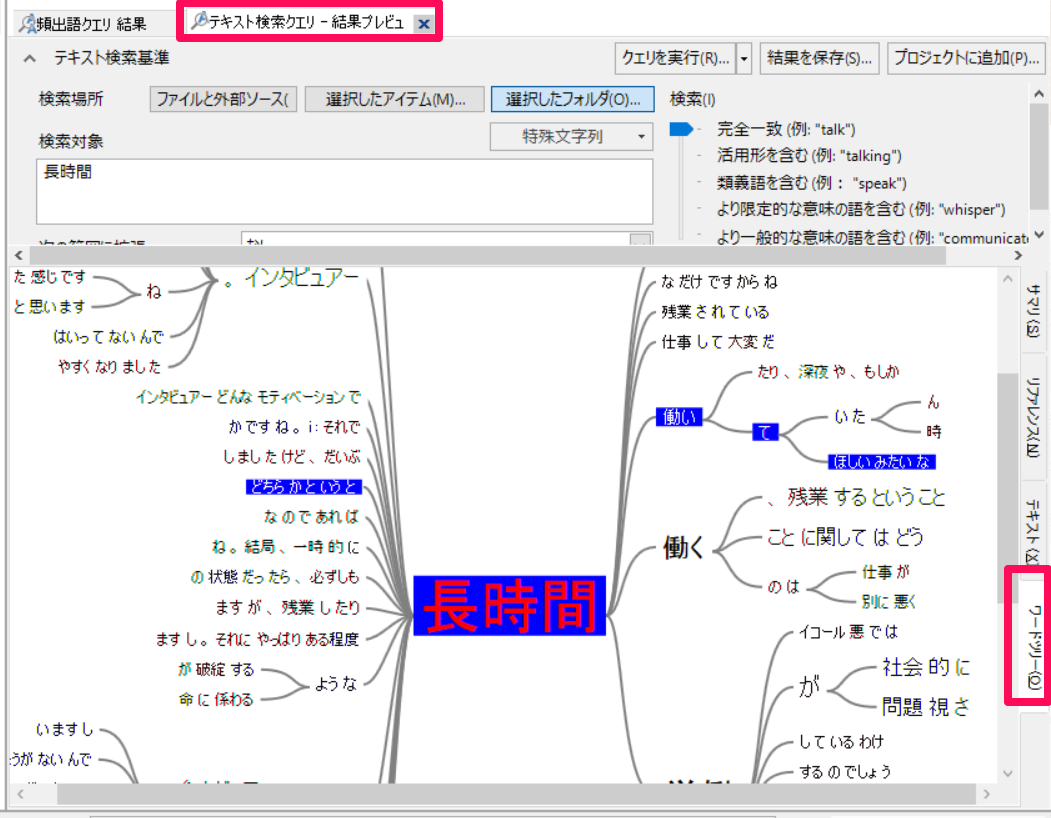
語を選び右クリック→[テキスト検索クエリを実行]で、単語クラウドからテキスト検索クエリを実行し、ワードツリーなどで前後を確認することもできます。
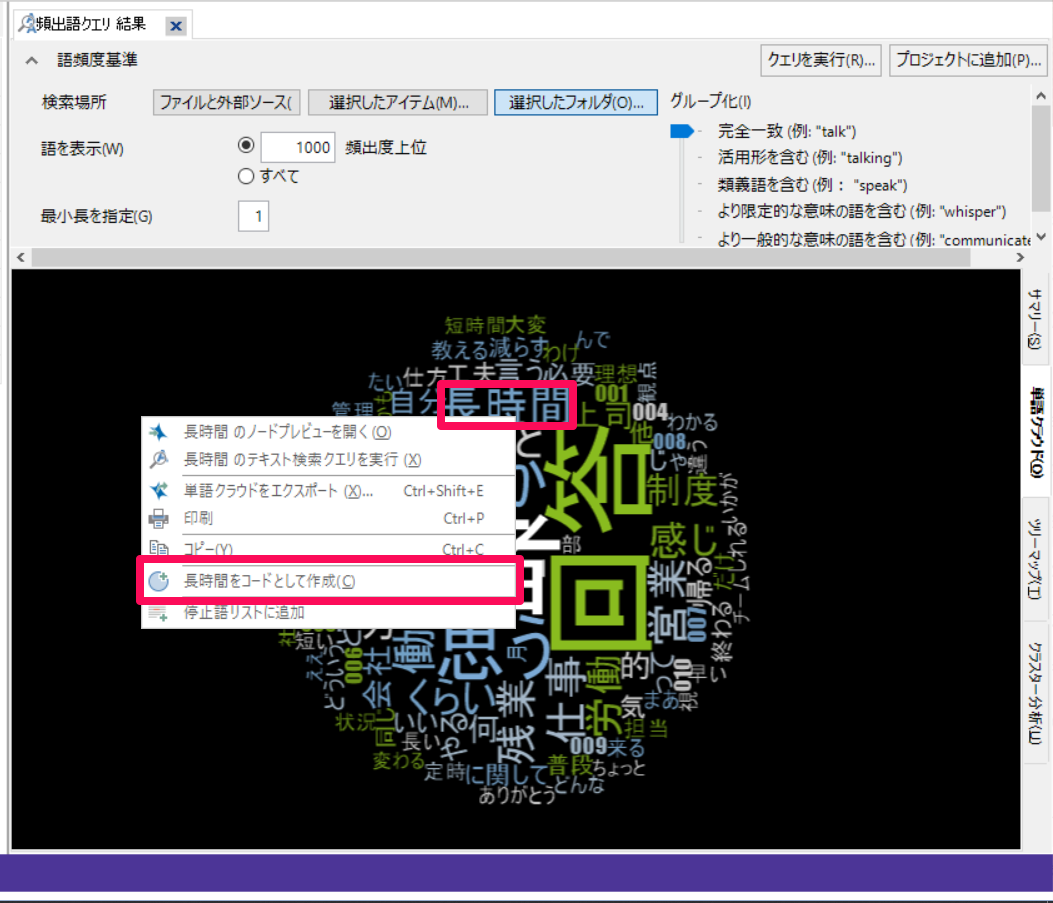
もしくは語の上で右クリック→[コードとして作成]をすることもできます。
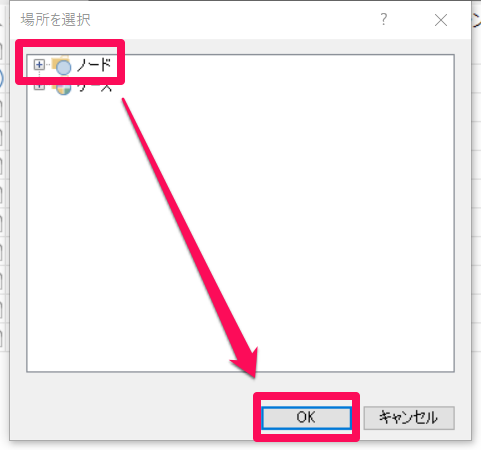
ノードを作成する場所を指定して[OK]。
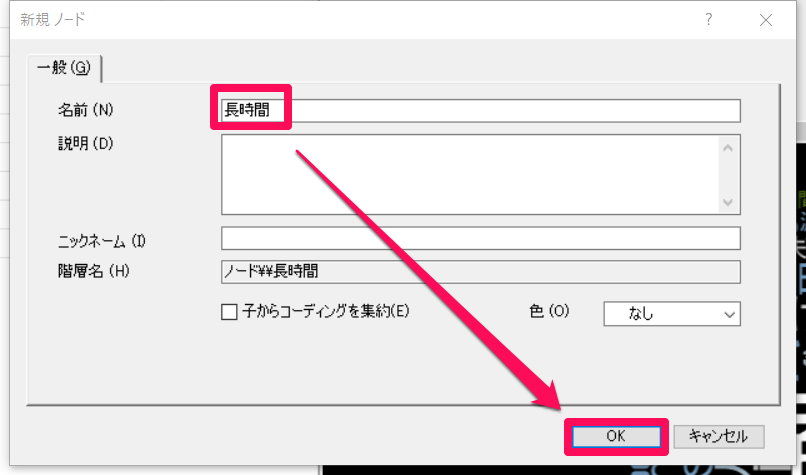
ノードの名前をつけると選択した語がノードにコーディングされます。
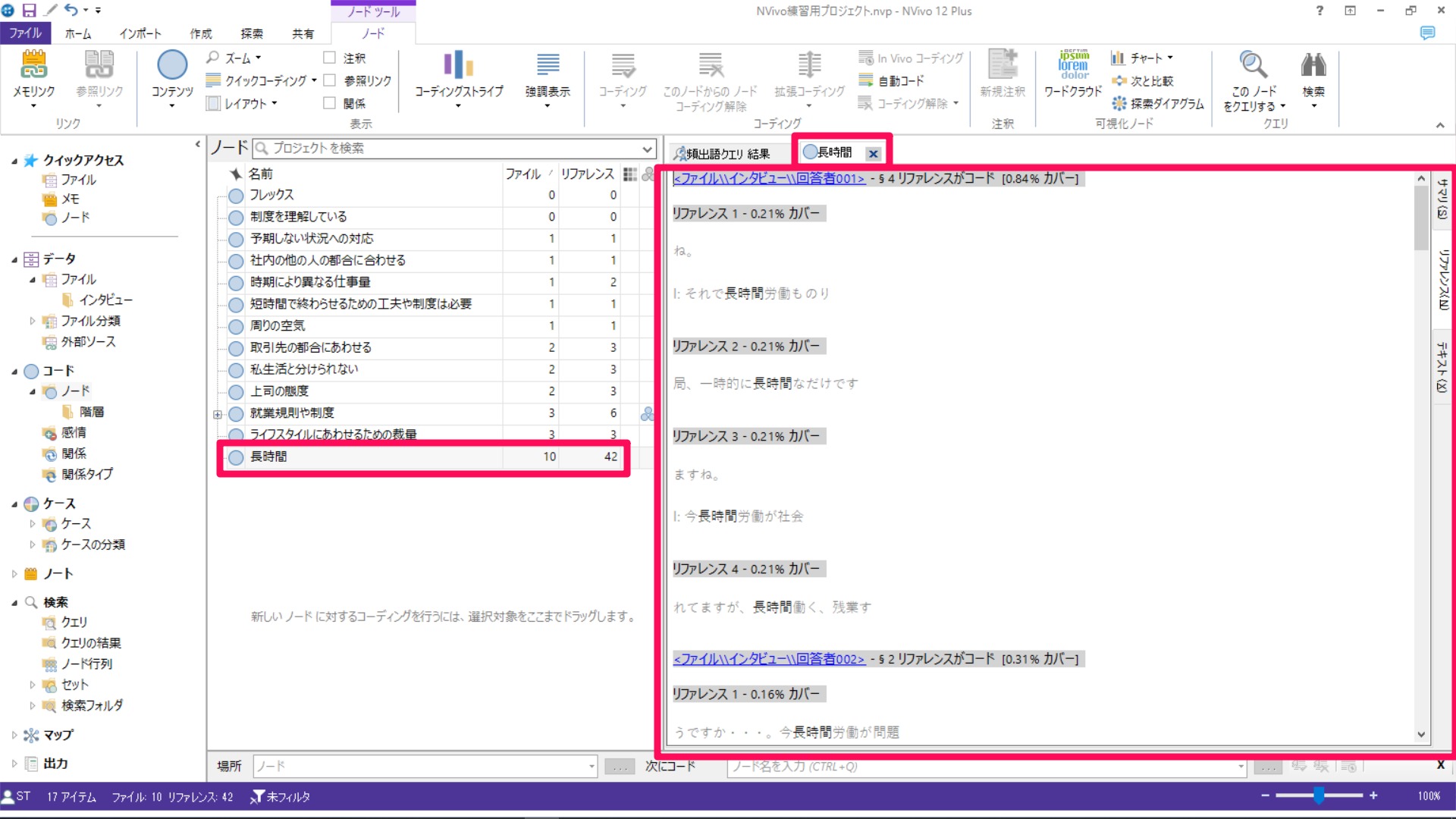
作成したノードを開いてみると、選択した語(ここでは「長時間」)のみがコーディングされていることが確認できます。
[拡張コーディング]機能を利用して、前後のコンテンツまで広げてみましょう。
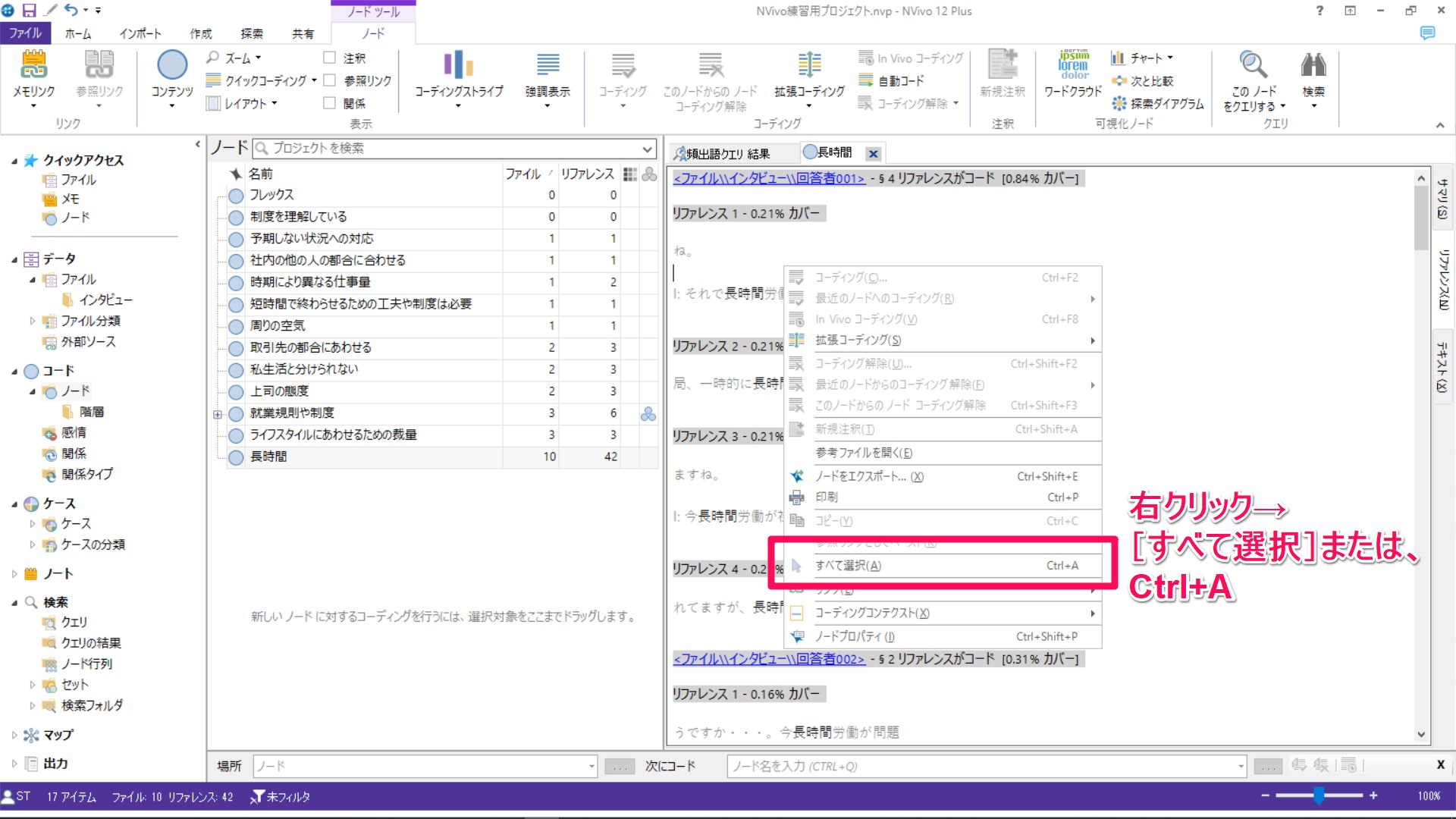
まずノードの中のテキストを全て選択します。
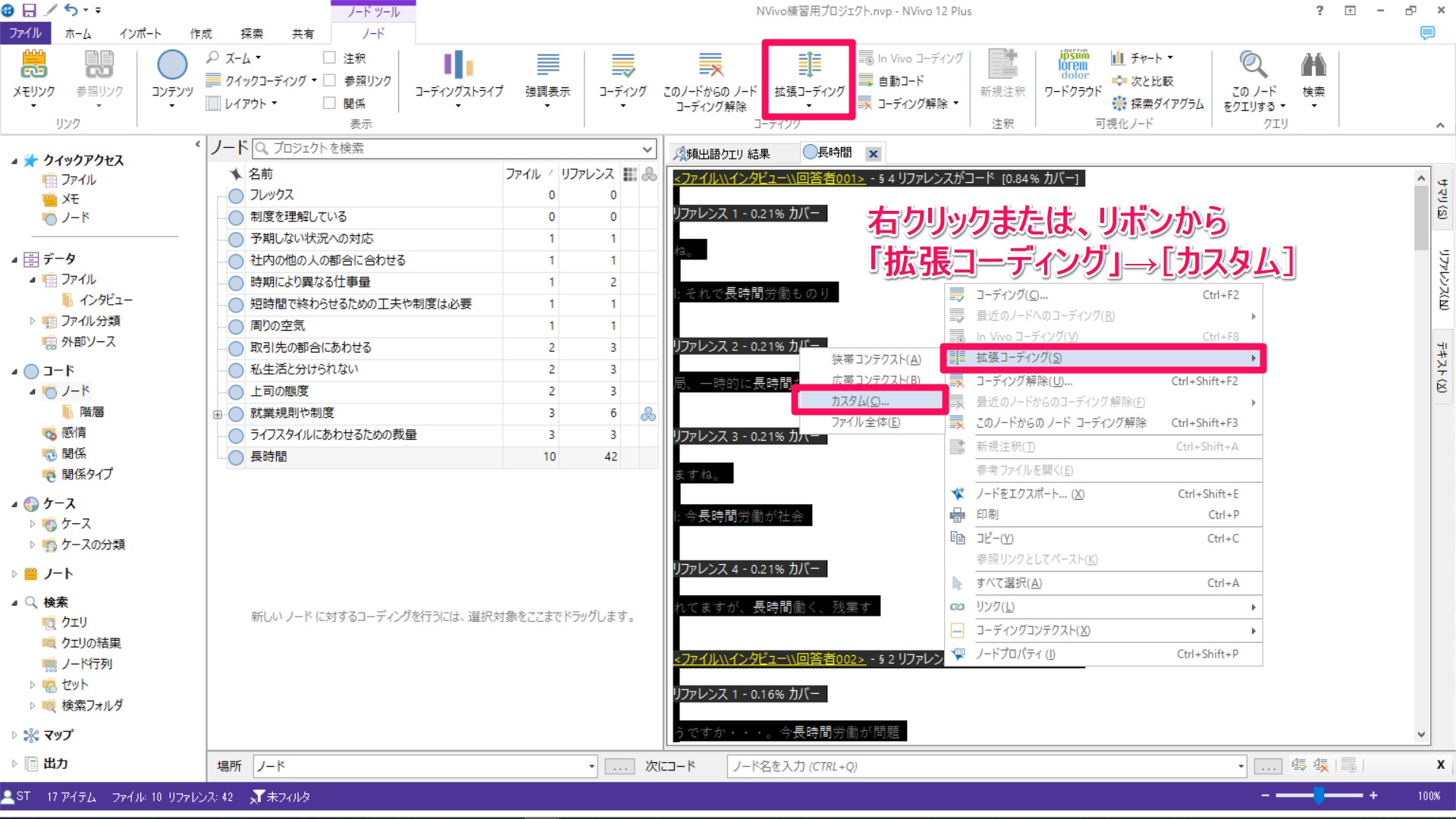
右クリックまたは、リボン[ノードツール]のメニューから[拡張コーディング]→[カスタム]をクリック。
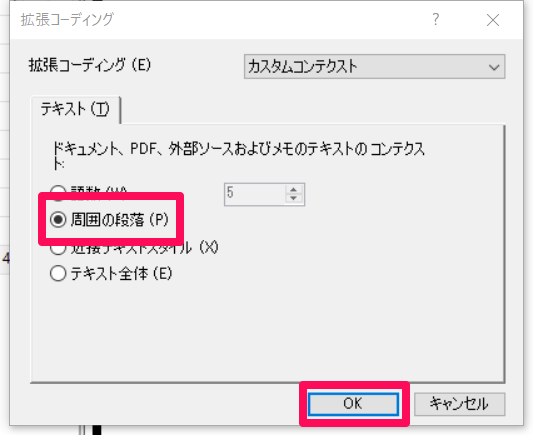
どの範囲まで拡張するかを選択します。ここでは[周囲の段落]を選び、選択した語(長時間)を含む段落を指定します。
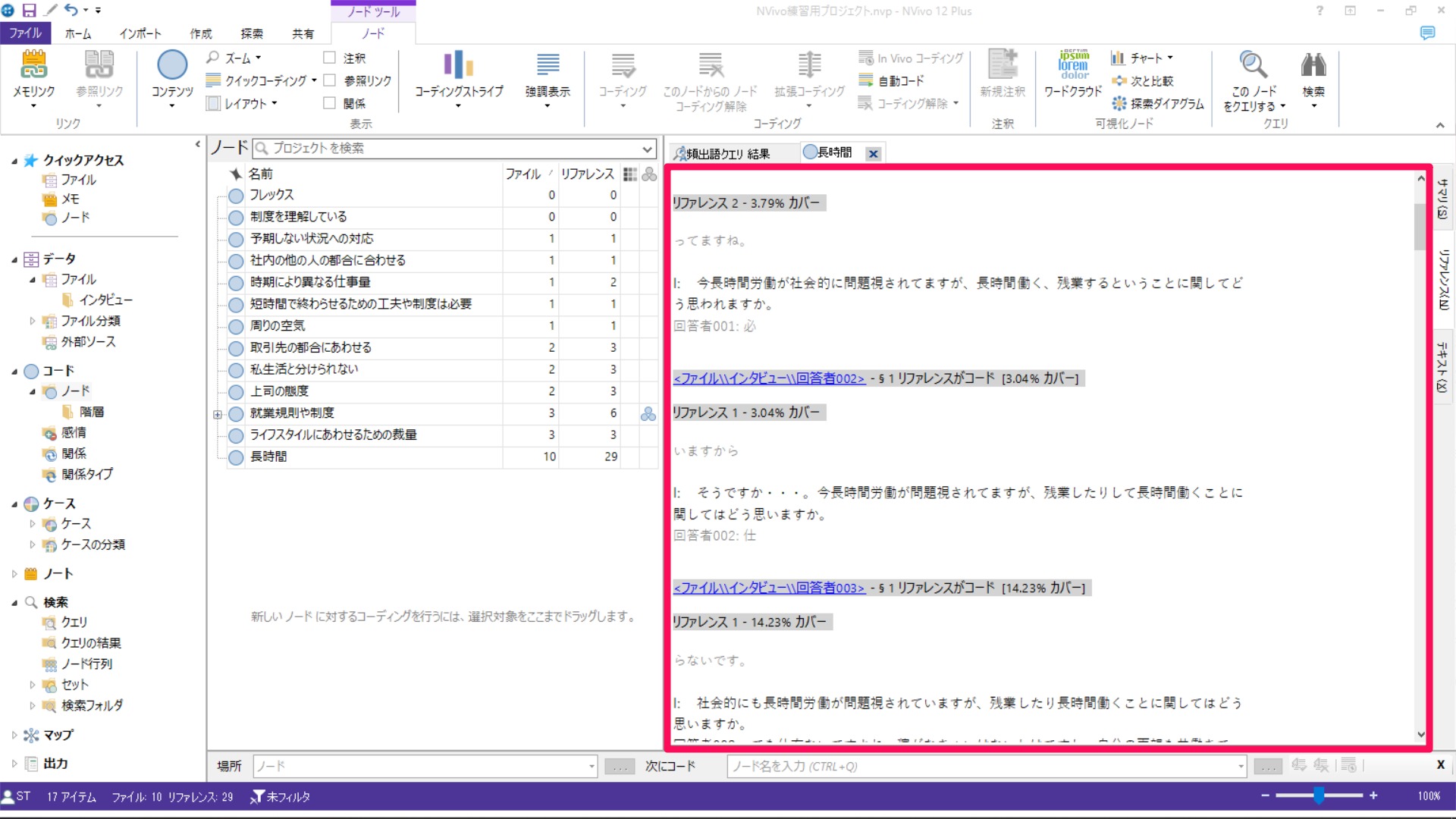
ノードにコーディングされているテキストが語(長時間)を含む段落まで拡張されました。

