
Webページの情報をMAXQDAやNVivoへインポート
Webサイトで参考になる情報を見つけた時、どのように保存していますか?
ブックマークしたり、PDFとして保存したり、EvernoteのWebクリッパーを使ったり、もしくは紙に印刷する場合もあるかもしれません。
MAXQDAやNVivoのユーザーであれば、もう一つ便利な方法があります。今回はMAXQDAとNVivoそれぞれが提供する以下のWebブラウザの拡張機能を使って収集、インポートする方法をご紹介します。
これらを利用するとWebサイトに掲載されている記事などを研究に関連する情報としてQDAソフトウェアに取り込むことができます。気になる情報を見つけた時にボタンをクリックしておくだけ。後でソフトウェアを立ち上げた時にまとめてインポートできます。
※NCaptureについては、NVivo 12 for Windowsの情報に基づいて記載しています。NVivo最新バージョンでは機能等ことなる場合がありますので、検証後に情報を更新します。
NCapture: NVivoが提供するWebブラウザ拡張機能
※ 以下は前バージョンのNVivo 12 for Windowsを使用しておりますが、現行バージョンでも操作手順はほぼ変わりません
Web上のデータを取得するにはNVivoの無料アドオンであるNCapture(エヌ・キャプチャー)を使用します。NVivoをインストールする時に、Internet ExploreもしくはChrome用のNCaptureを同時にインストールすることができます。それぞれのブラウザ上にNCaptureのボタンが表示されていることを確認してください。インストールされていない場合は開発元のダウンロードサイトより入手できます。
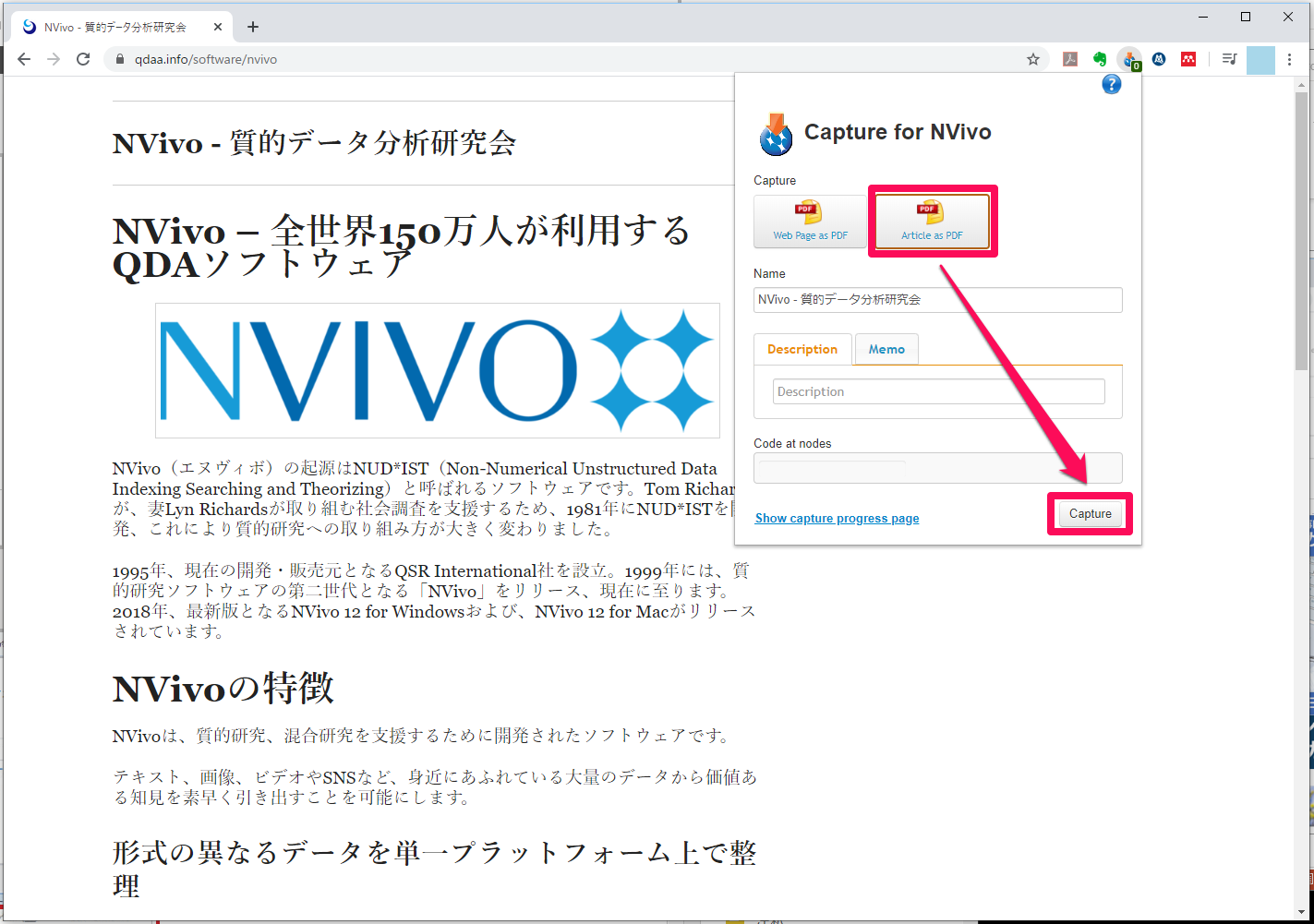
ブラウザ(ここではChromeを使用)の右上にNCaptureのボタンが表示されています。
保存したいページを表示し、[NCapture]ボタンをクリック。

NCaptureが表示されます。Webページを保存する場合、画面表示のまま保存する[web page as PDF]と、サイドの広告などを省いて保存する[Article as PDF]のいずれかを選択します。
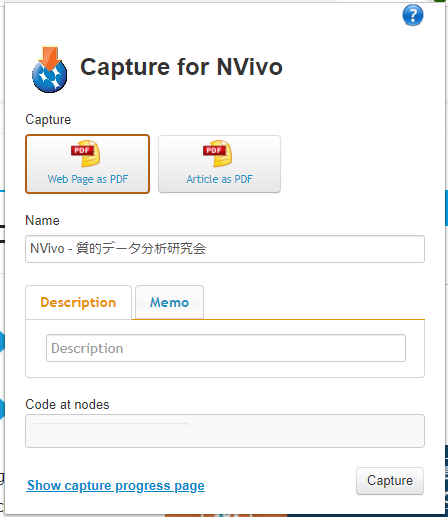
ここでは[Article as PDF]を選択、サイドのバナーなどが省かれている状態で[Capture]。
キャプチャが完了しました。

NCaptureではTwitter、facebook、YouTubeをデータセットまたは、Webページとして保存することもできます。例えばTwitterでは、以下のようにツイートのみまたは、リツイートを含めてデータセットで保存するか、画面に表示されたままPDFとして保存するかを選択できます。
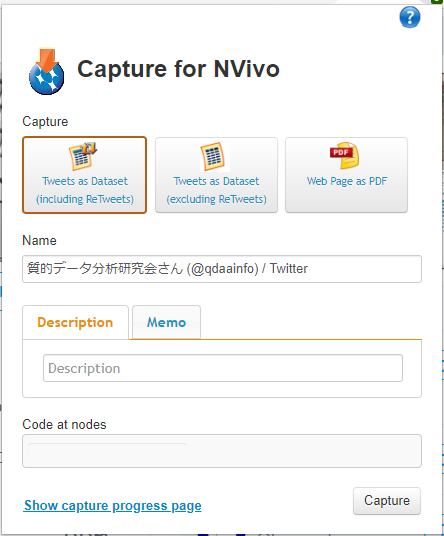
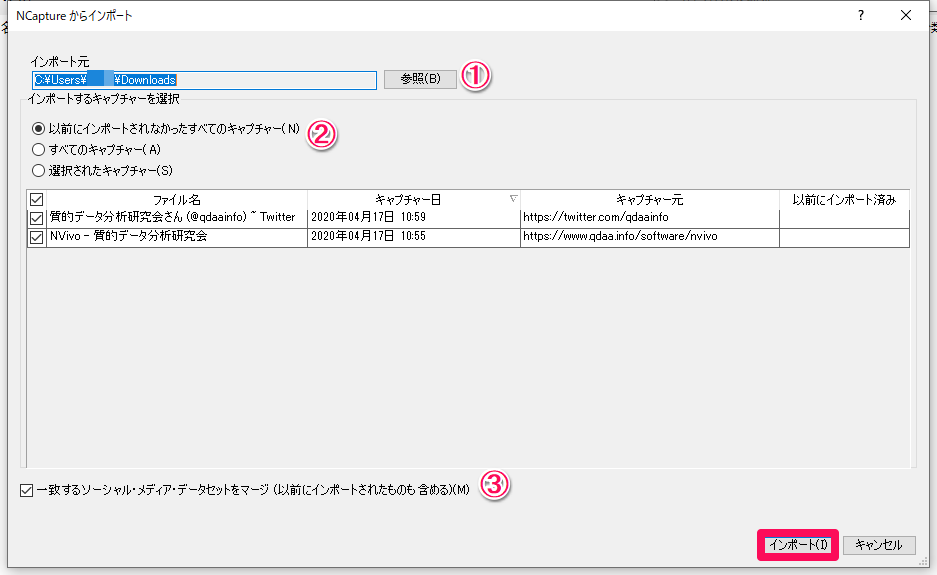
このように[NCapture]を使い、気になる情報をどんどん保存しておきます。都合の良い時にNVivoを起動し、これらのデータをインポートしておきましょう。リボン[インポート]>[NCapture]。
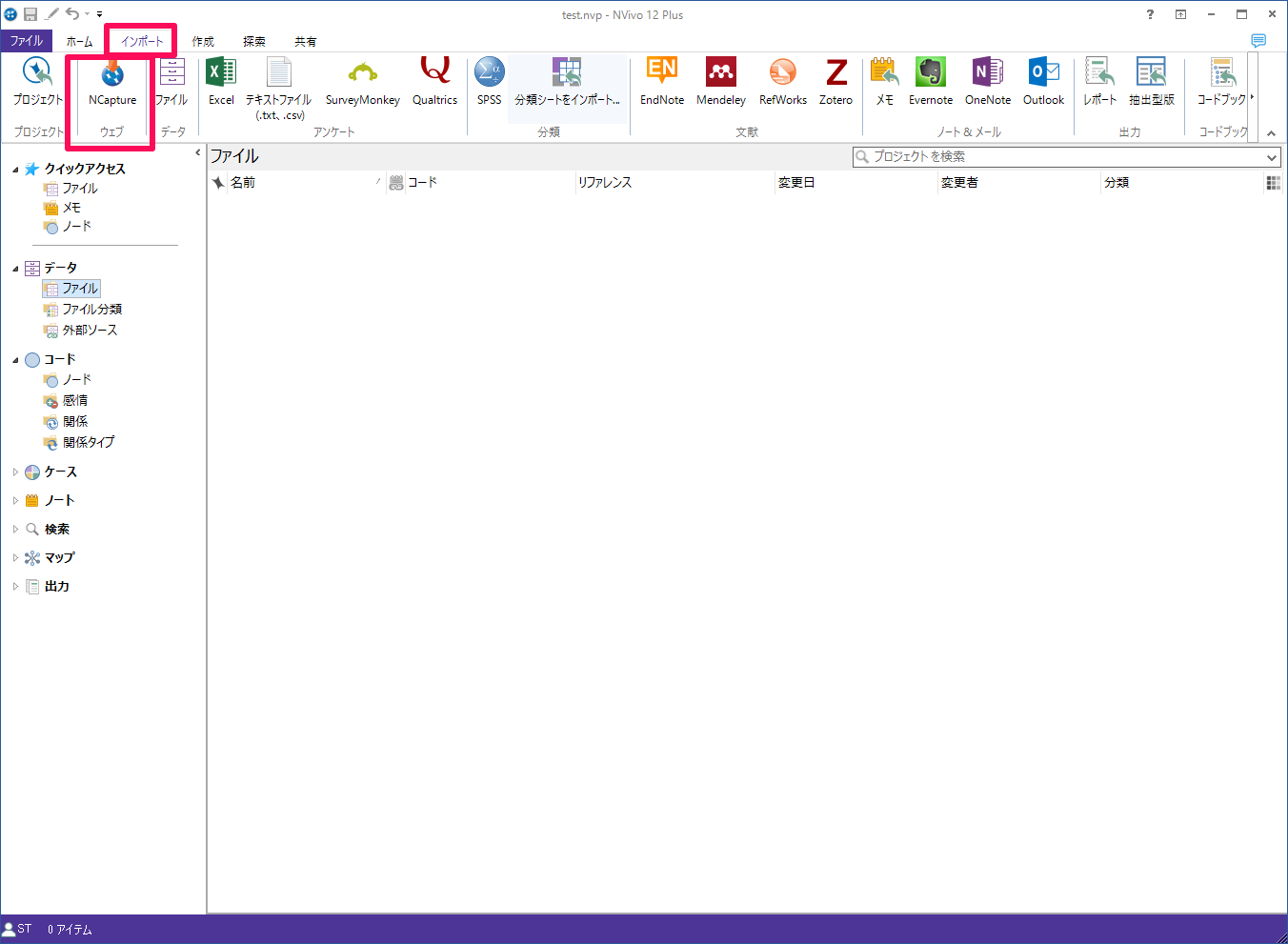
①NCaptureで保存したフォルダを指定(標準ではダウンロードフォルダに保存されます)
②どのファイルをインポートするかを指定
③ソーシャルメディアデータの場合、以前にインポートしたファイルとの差分だけをインポートできます。
指定完了後、[インポート]。
インポートされました。あとは他のデータと同じようにコーディングなどで整理、分析していくことができます。
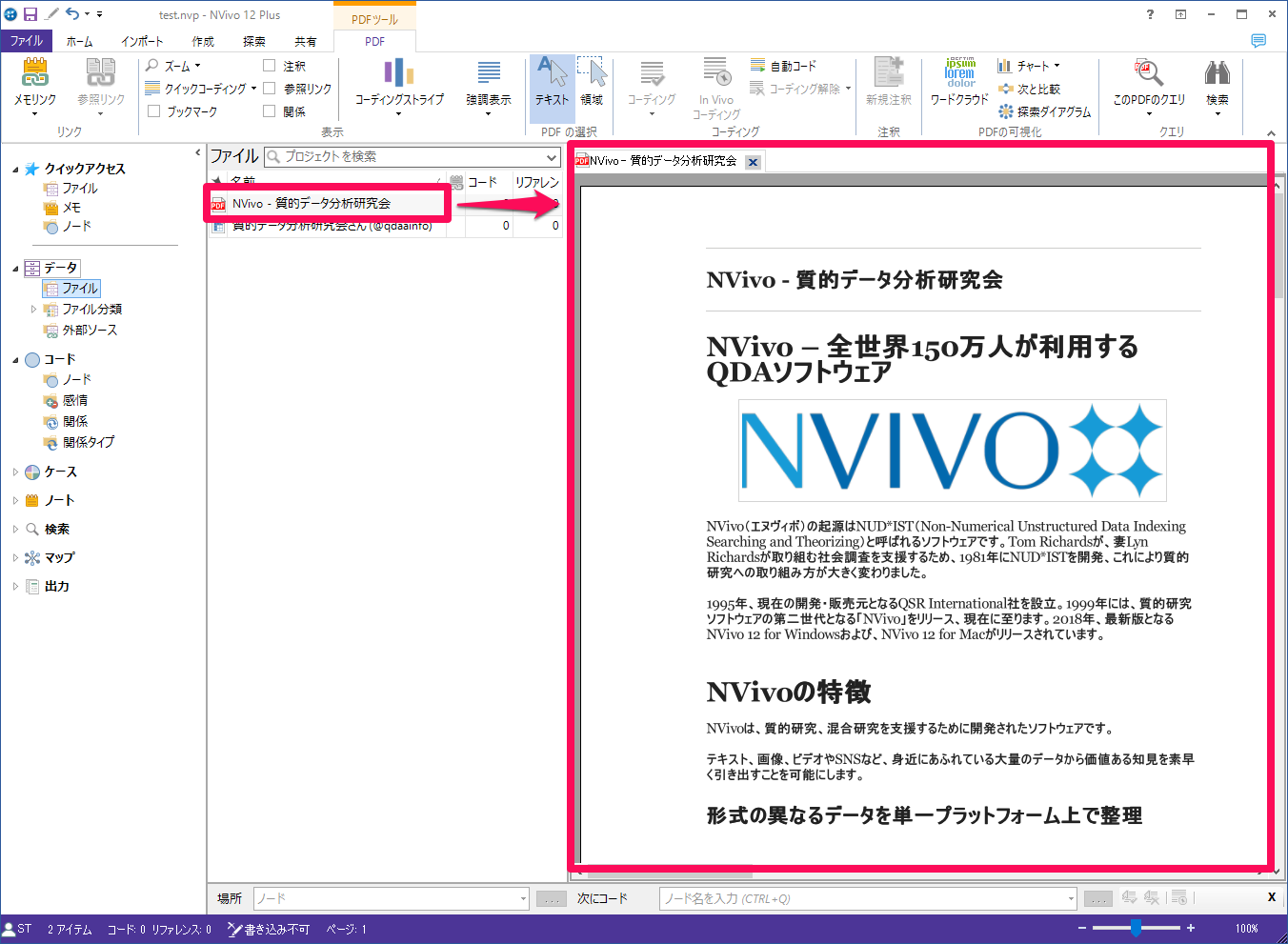
PDFで保存されたwebページ
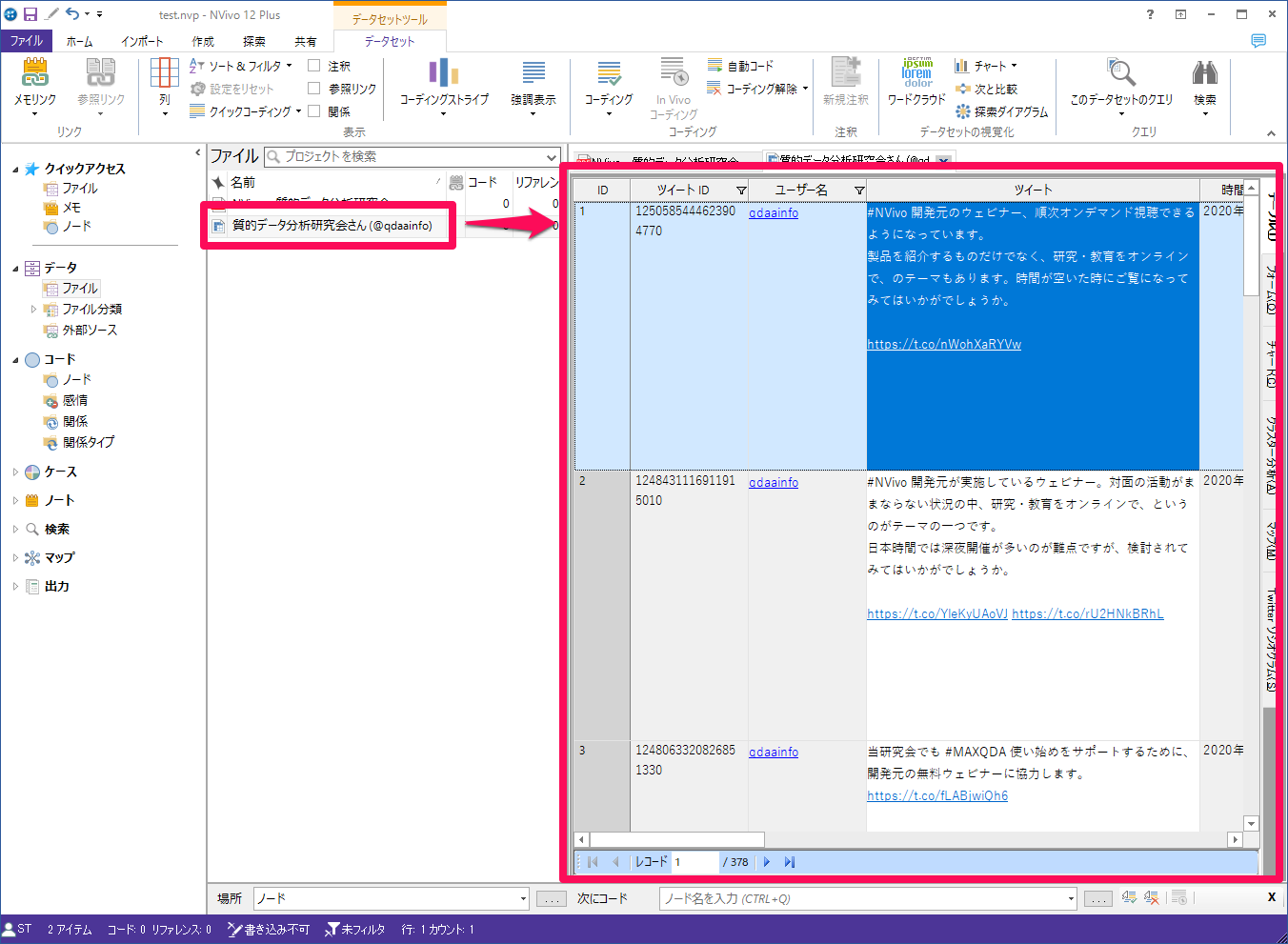
データセットとして保存されたツイート
Web Collector:MAXQDAが提供するWebブラウザ拡張機能
Webページを所得するための拡張で機能で、Chrome上で利用できます。
Chromeウェブストアで詳細を確認し入手してください。
- Web Collector for MAXQDA (MAXQDA 2022 / MAXQDA 2022 をお使いの方)
- Web Collector for MAXQDA 2018 and 12 (MAXQDA 2018 / MAXQDA 12 をお使いの方)
※ MAXQDA 2022でwebページ収集方法が拡張されました。
参考: WebページをMAXQDAへインポート
Chromeの右上にWeb Collectorのボタンが表示されています。
保存したいページを表示し、[Web Collector]ボタンをクリック。
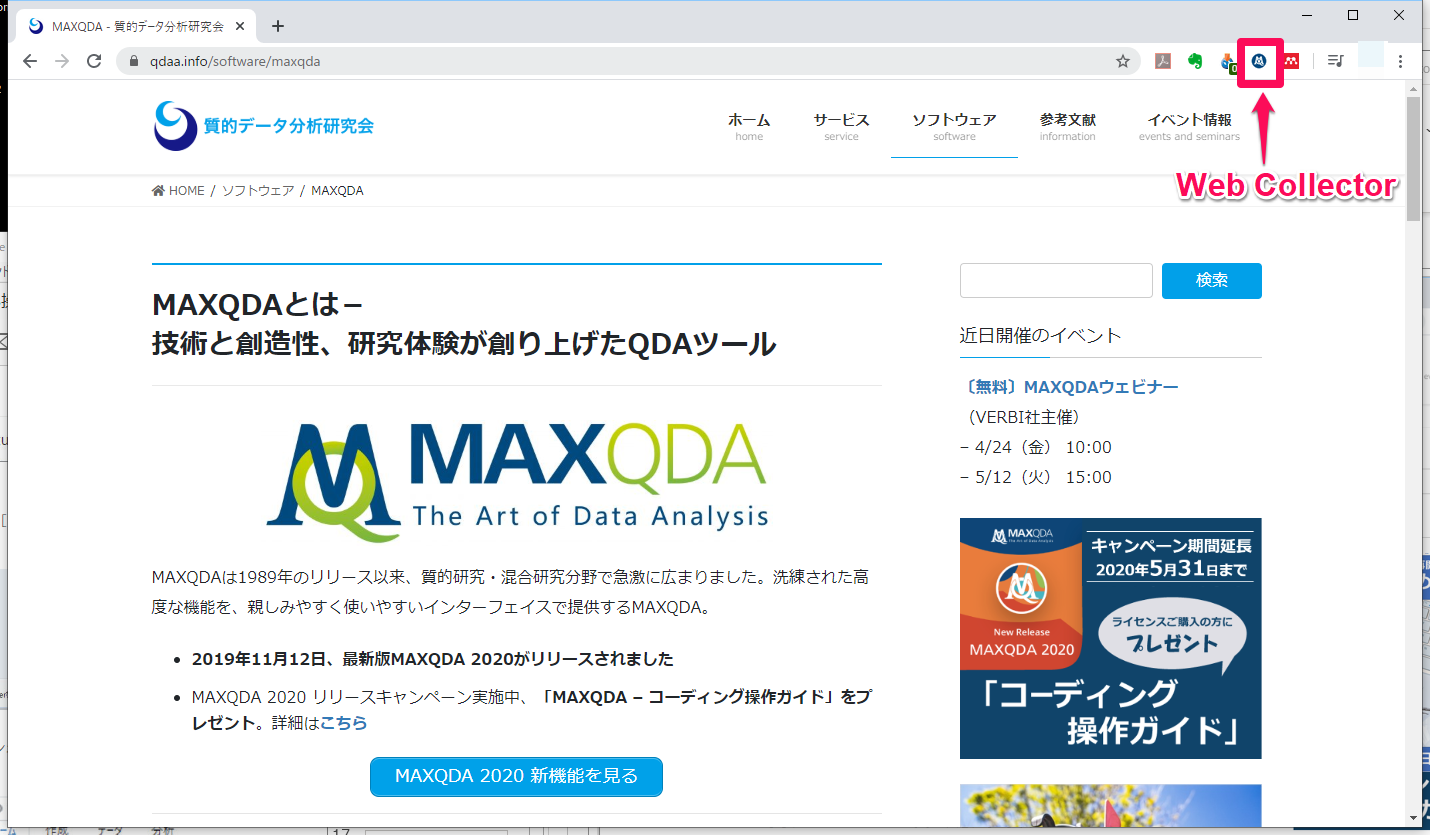
Web Collectorが表示されます。Webページを保存する場合、画面表示のまま保存する[web page]と、サイドの広告などを省いて保存する[Simplified Web Page]のいずれかを選択します。
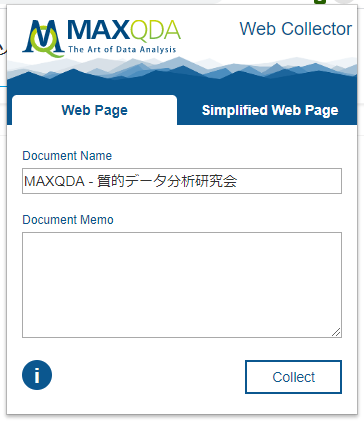
いずれか(ここでは[Simplified Web Page])を選択し、[Collect]。
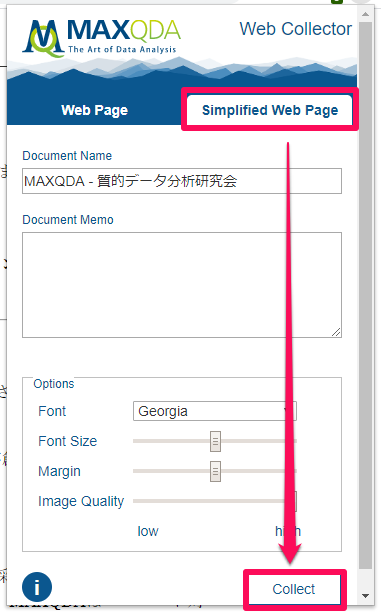
完了するとファイルがダウンロードされ、[Web Collector]インポート手順が表示されます。
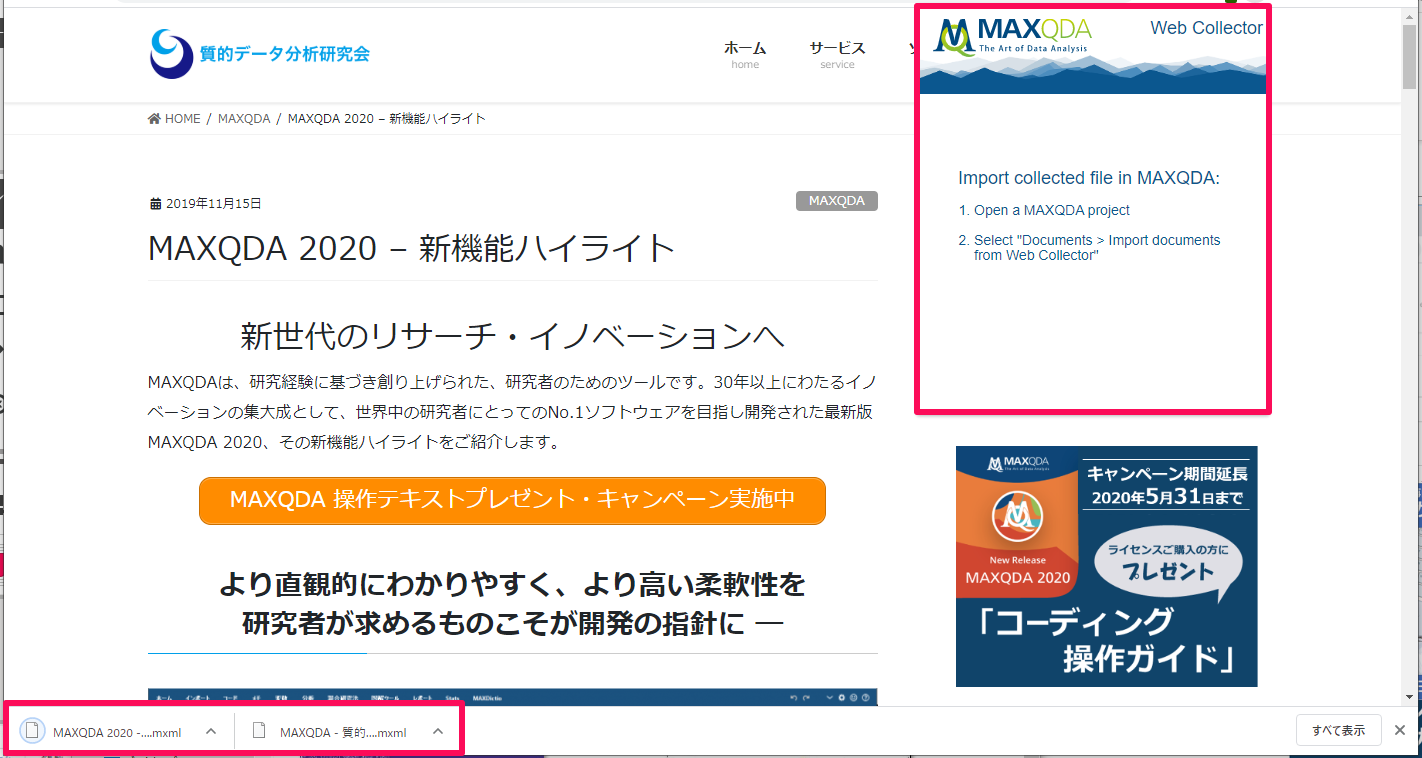
このように[Web Collector]を使い、気になる情報をどんどん保存しておきます。都合の良い時にMAXQDAを起動し、これらのデータをインポートしておきましょう。リボン[インポート]>[Web Collectorデータ]。

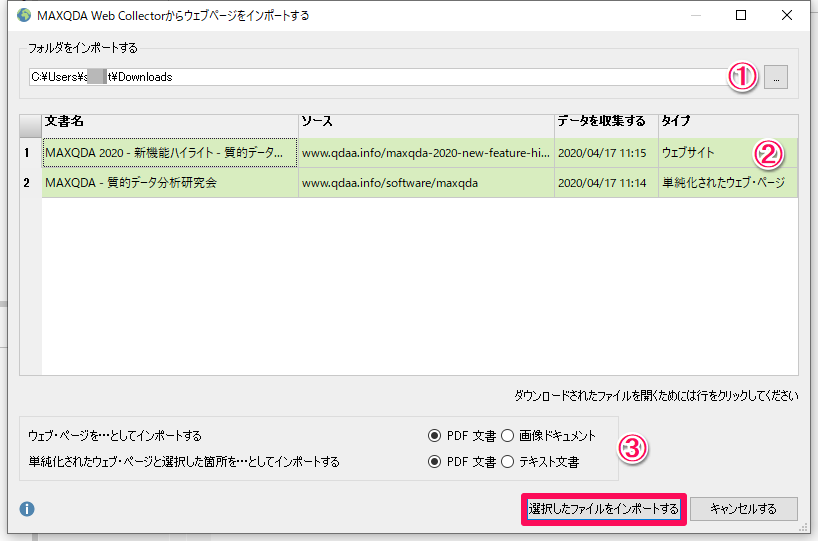
①Web Collectorで保存したフォルダを指定(標準ではダウンロードフォルダに保存されます)
②どのファイルをインポートするかを指定
③MAXQDAに読み込む形式を選択
– Webページの場合:PDFまたは、画像
– 単純化された(Simplified)webページの場合:PDFまたは、テキスト
※単純化されたwebページの場合、テキストで読み込むとMAXQDA内で編集が可能になります。
指定が完了したら[選択したファイルをインポートする]。
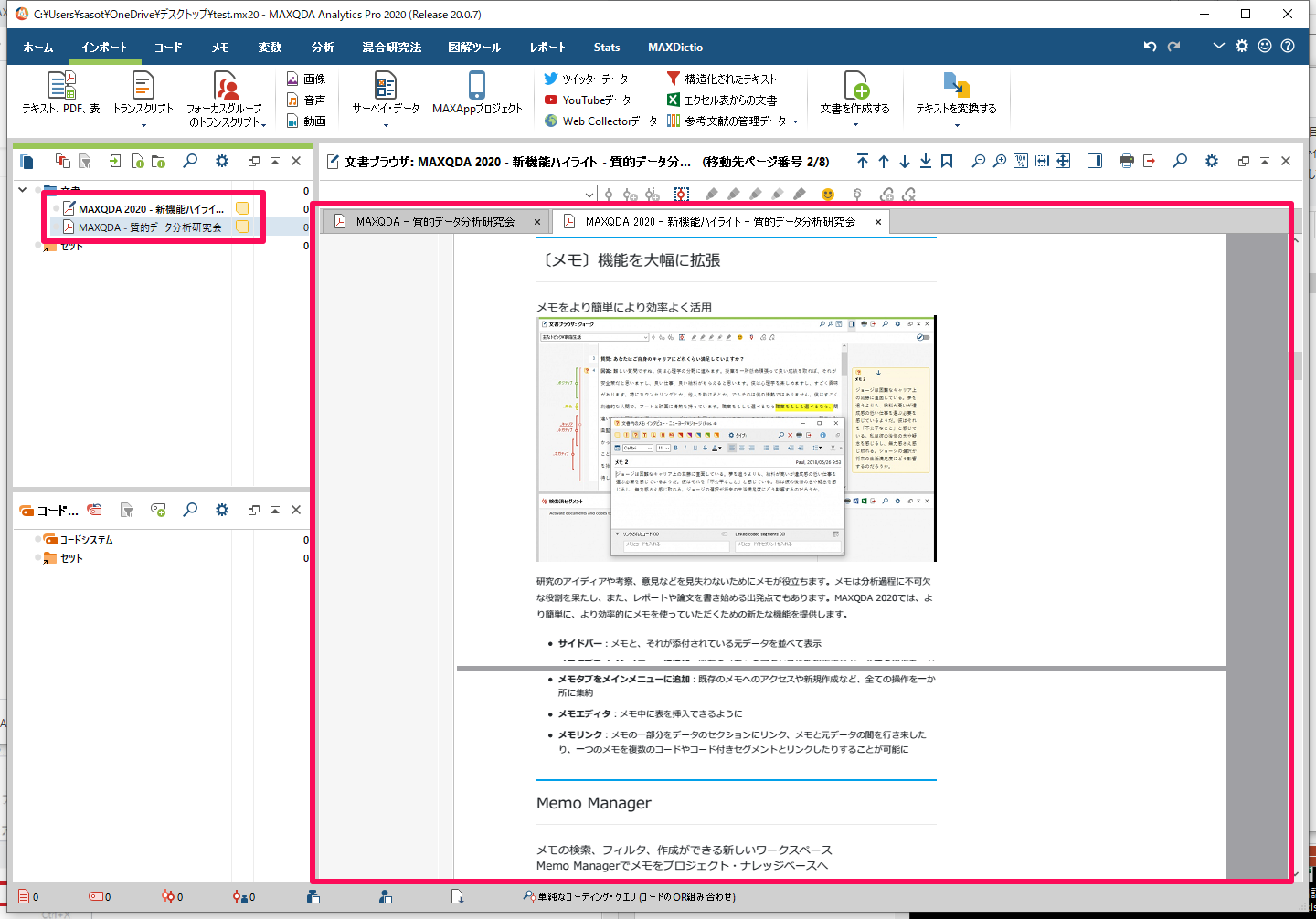
インポートされました。あとは他のデータと同じようにコーディングなどで整理、分析していくことができます。
さまざまな情報を入手できる環境の中、ともすると大量の情報が集まりどこに保存したか見失ってしまった経験はだれしもあることと思います。研究に関連する情報などは先行論文のPDFなどとともにMAXQDAやNVivoで管理、整理してみてはいかがでしょうか。


