
MAXQDAの語彙検索・自動コーディング機能を活用し、COVID-19に関する知識にアクセス
MAXQDA Research Blog 翻訳版
Post by Prof. Dr. Udo Kuckartz(Thursday, September 3, 2020)
※ 本文中の新型コロナウイルス感染症に関する記述は原文投稿時点情報を元にしたものです。
※ 文中で紹介されている機能のスクリーンショットを掲載しています。これらはMAXQDAが提供するサンプルプロジェクトを使用し当会が作成したもので、表示されたデータや出力は本文とは異なりますのでご了承ください。
2020年2月の初め、コロナウイルス時代の初期には、COVID-19の原因となるウイルスについての知識は非常に限られていました。ウイルスが拡散するにつれて、ドイツに住むあらゆる層の国民が情報を求める声が高まっていきました。その点では、私も世界中の何百万人もの人々と同じように感じていたのです。3月に入ってから、タブロイド紙、ラジオ、テレビ、科学雑誌、大学のウェブサイトのプレプリントなど、あらゆるメディアがこの情報ニーズに応えようとしていました。私はリスクグループの条件に当てはまるため、パンデミックが始まった当初からCOVID-19についてわかっていることをすべて知りたいと思っていました。しかし、その後の数週間、数ヶ月の間に情報量は指数関数的に増えていったのです。そこで私は、MAXQDAを利用することを思いつきました。
MAXQDAは、研究におけるデータ分析のための強力なツールであるだけでなく、研究データの分析以外にも有効に活用することができます。例えば、多くの人が文献レビューやEndNoteやCitaviなどのレファレンスマネージャーとのやりとりにMAXQDAを使っています。
MAXQDAを活用して、COVID-19について、その症状、潜伏期間、発病期間や経過、その他多くの疑問点など、急速に増えている知識に素早くアクセスすることができました。特に活用した機能は、検索と自動コーディング機能です。以下では、ポッドキャストデータの書き起こしを例に、これを凝縮した形で説明します。
ドイツでは、ウイルス学者のドロステン教授が、連邦政府やアンゲラ・メルケル首相のアドバイザーとして、また公的な場でも重要な役割を果たしています。ドロステン教授は、ベルリンのフンボルト大学の大学病院であるシャリテでウイルス学の主任医師を務めています。2020年2月26日から6月23日まで、初期には毎日、後に週一回配信となったNorddeutscher Rundfunk (NDR)のポッドキャスト「コロナウイルス・アップデート」で、ドロステン教授はCOVID-19に関するすべての質問に対応していました。
データの準備
NDRでは、すべてのポッドキャストをメディアライブラリで自由に利用できるようにしています。これらのポッドキャストはMP3ファイルとして簡単にダウンロードできます。また、すべてのポッドキャストを書き起こしたトランスクリプトをPDFファイルとしてダウンロードすることもできます。私は2月から6月末まで定期的にこれらのファイルをダウンロードし、50の音声ファイルと50のPDFファイルのコレクションを作成しました。音声ファイルはすべて MAXQDA にインポートして、文書グループ「Drosten podcasts audio」に、トランスクリプトは文書グループ「Drosten podcast transcripts (PDF)」に保存しました。
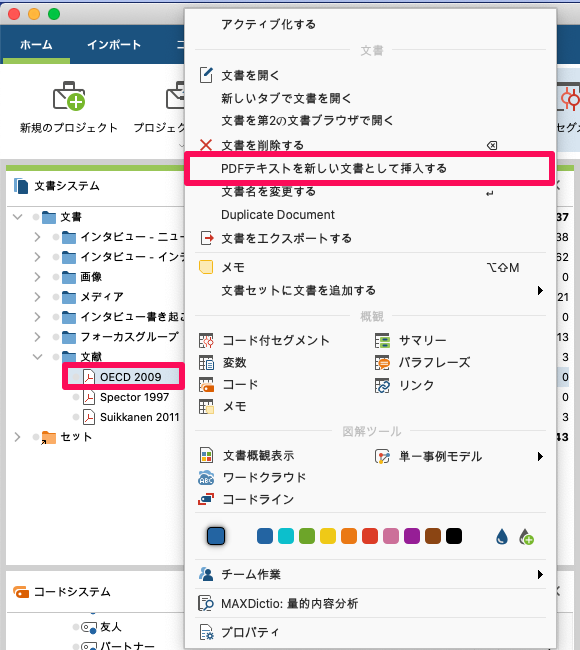
音声ファイルとPDFファイルのインポート後、データ準備のために追加作業をしました。このステップは絶対に必要なものではありませんが、その後の分析の選択肢を増やすことができます。PDF 形式のトランスクリプトを DOCX ファイルに変換しました。これは MAXQDA で、「PDFテキストを新しい文書として挿入する」という機能を使って行います(それぞれの文書の右クリックで表示するコンテキストメニューで利用できます)。次に、「Podcast date」という名前の文書変数を作成し、ポッドキャストのそれぞれの日付を入力しました。こうすることで、いつ何かが伝達されたかがすぐにわかるようになりました。これにより、ある期間のポッドキャストだけを使って作業することも可能になりました。
語彙機能で体系的に情報を探す
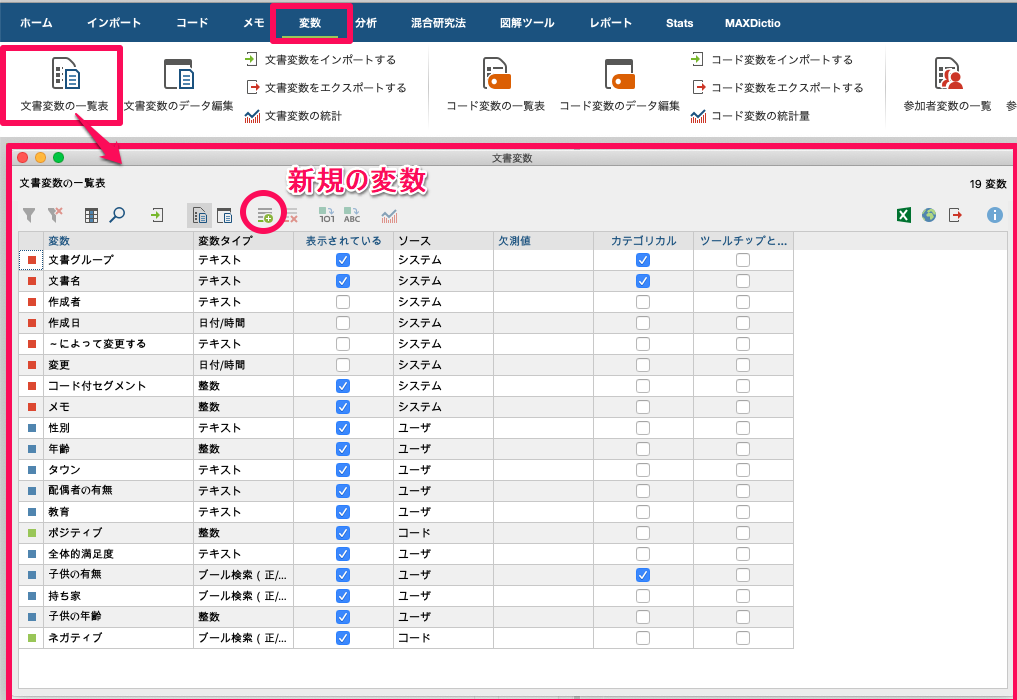
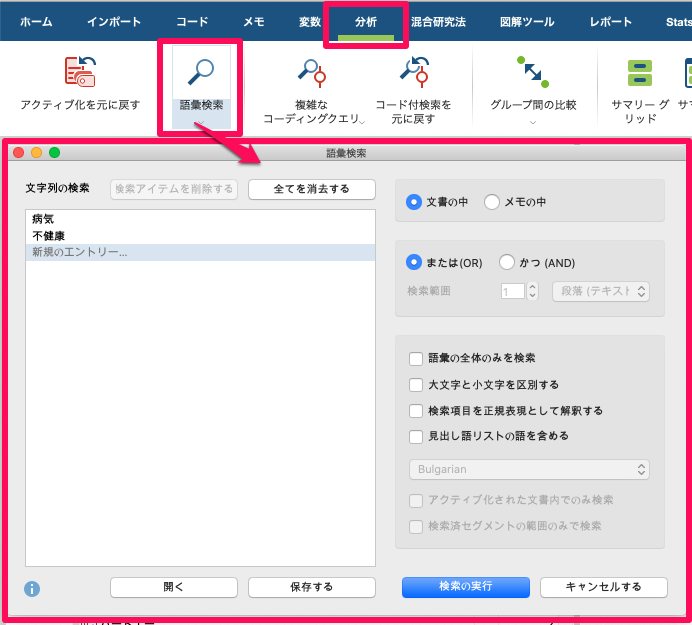
語彙検索機能(「分析」タブ内)により、ポッドキャストデータから情報をコンパイルする可能性が広がりました。ここでは、検索語を入力して、何がヒットするかを判断することができます。検索自体には、「単語全体を検索」や「大文字小文字を区別して検索」などの便利なオプションがあります。また、見出し語リストから単語をまとめることもできます。見出し語化は、単語の形を基本形である見出し語に還元します。そのため、例えば「failures」も「Failure」も同じように、「failure」としてまとめられます。
※ 見出し語化の機能は、2021年1月現在日本語テキストでは使用できません
単純な検索でも数秒で役に立つ結果が出てきます。例えば、「潜伏期間」で検索すると、このテーマについての発言が驚くほど少ないことがわかります。このトピックは、3月3日のポッドキャスト第5回で初めて言及されています。その時は、潜伏期間の中心は2日から7日の間であるとされていました。その後、英国の研究に基づき、潜伏期間は平均5日から6日、場合によっては14日まで想定されるようになりました。3月18日のポッドキャスト16では、インペリアル・カレッジ・ロンドンの研究者グループがモデルを構築する際に5.1日の潜伏期間を想定していることを知りました。ポッドキャスト50本のうち、「潜伏期間」というトピックが含まれているのは9本だけです。すべてのポッドキャストから集められた発言を要約すると、潜伏期間についての信頼できる知識はまだほとんどなく、情報も曖昧であることがわかります(例えば、潜伏期間の標準偏差についての情報はありません)。この情報は、もちろん、個人や政府の対策にも大きな関連性があります。
MAXQDAでは、検索語を組み合わせることもできるので、「日」と「感染」の検索クエリで以下のような結果が得られました。「感染した人は症状が始まる前日が最も感染力が強く、4日後、長くても7日後には明らかに感染力がなくなっている。その後、ウイルスは遺伝物質としてしか検出されない」 (3月22日のポッドキャスト34)
検索クエリに検索語が多く含まれている場合や、「見出し語リスト」機能を利用している場合は、検索クエリを保存しておくと、後で再入力しなくても済むので便利です。
関心のあるトピックを自動コーディングする
新しいポッドキャストのトランスクリプトがデータベースに追加された場合、特定のトピックに関する発言をゼロから検索していきます。しかし、検索したテキストセグメントによって情報のレベルが大きく異なることにすぐに気づくでしょう。単なる繰り返しもあれば、非常に詳細な内容もあります。そのため、あるトピックで検索された結果すべてを何度も読み返すのはあまり効果的ではありません。これを避けるための優れた方法は、自動コーディングの際、興味のないパッセージには コード化しないようにマークを付け、そのパッセージをコーディングから除外することです。これは、MAXQDA の自動コーディング機能の大きな利点です。検索結果のすべてのテキストのパッセージを単に盲目的にコーディングするのではなく、ユーザーが本当に重要なものを選択できるようにしてくれます。一度このように検索結果を精査しておけば、後でコード付きセグメントを見直す際、例えば「潜伏期間」というトピックの重要で新しい情報を含むものだけがリストアップされます。

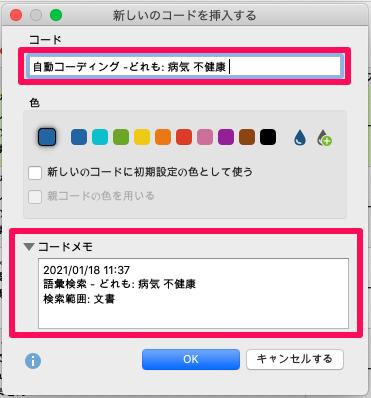
ドイツでは「子供は感染するのか」「どの程度まで感染力があるのか」ということが非常に物議を醸していました。同じ文章の中に「子供」と「感染症」という言葉が出てくるものを検索すると、15回のポッドキャストで58件のヒットがありました。この話題が本当に重要視されるようになったのは第36話(3月28日)以降で、それまではほとんど注目されていませんでした。私は結果の表をめくって、あまり興味のない文章に印をつけました。さて、ここで私はどこまでをコーディングするかを決めなければなりません。MAXQDA は、ここでも多くの可能性を提供してくれます。検索文字列だけをコード化することも、文章だけをコード化することも、段落全体をコード化することもできます。また、「文」と「段落」というオプションを使えば、ヒットした語を含む文または、段落の前後いくつの文や段落をコード化するかを指定することもできます。
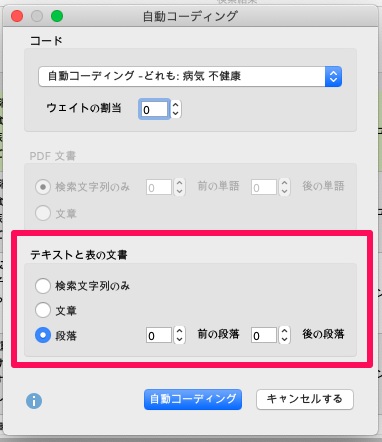
自動コーディング機能は、常に「自動コーディング」という言葉で始まるコードを作成し、選択したオプションをコードメモとして記録するので、どのデータがどのような方法で自動的にコード化されたのかを後から常に確認できます。
辞書を使った自動コーディング
MAXQDA の有効な機能は、自分で作成した辞書を使って自動コーディングすることです。このような辞書は、MAXDictio モジュールを使って作成することができます。近いうちに、別のブログ記事で、この形式の自動コーディングがコロナウイルスのデータでどのように機能するのかを説明する予定です。
「コロナウイルス・アップデート」のポッドキャストを使った作業は、パンデミックについての知識をかなり広げてくれただけでなく、例えば、公的な言説の中でこの最も重要なドイツのウイルス学者の仕事の根底にはどのような証拠という暗黙の概念があるのかなど、メタレベルでの疑問を呼び起こしてくれました。
- この投稿は掲載元と著者の許可を得て、MAXQDA Research Blogより日本語訳したものです。
- 詳細は原文How I used the search and autocode functions of MAXQDA to access knowledge about COVID-19を確認いただくことをお勧めします。
参考: NVivoの使い方 – テキスト検索の結果をコードとして保存する


